Hello Kimi Support Team,
I am writing to report a critical service disruption that has completely blocked my workflow for the past 3–4 days.
Account Information:
-
Subscription: Allegretto
-
Account paid/active until: May 5, 2026
-
Client: KimiClaw (OpenClaw 2026.3.13, build 61d171a) via browser
-
Model used: kimi-coding/k2p5
Issue Timeline:
-
Until recently: Kimi worked perfectly with version 2.5 (k2p5). No issues.
-
3–4 days ago: Severe degradation began — response start times increased to minutes, constant session hangs and disconnections.
-
This morning: Complete block. Every request returns “The engine is currently overloaded, please try again later”. I cannot get any response at all.
Specific Errors (see attached screenshots):
-
“The engine is currently overloaded, please try again later” — repeating on every single request, making the service unusable.
-
“Compaction failed: Compaction cancelled • Context ?/131k” — context compression broke entirely. The session became a “zombie” that could not be recovered.
-
Context overload state: Before the total failure, the client showed:
-
Context: 119k/131k (91%)
-
Cache: 99% hit • 119k cached, 0 new
-
Compactions: 20
-
Session: agent:main:main
-
Think: high • Reasoning: stream • Queue: collect (depth 0)
-
My Situation:
I am a solo developer relying entirely on Kimi for a single project. My entire workflow runs through Kimi: planning, backend code, frontend code, CI/CD deployment management, and documentation. This outage has completely stopped my development.
Attempted Solutions:
-
Sending
\new— helped only for a very short dialogue, then the same errors returned immediately. -
Trying to clear/compact context — failed due to the compaction error above.
-
The issue appears only in KimiClaw (browser, mobile client). I have not tested the official web interface extensively because KimiClaw is my primary IDE-integrated workflow.
Additional Context:
I use a heavily customized agents.md file. KimiClaw previously confirmed it is valid/normal, but I can provide it for analysis if needed.
Request:
Please investigate:
-
Why the kimi-coding/k2p5 model is returning persistent “engine overloaded” errors for a paid Allegretto account.
-
Why context compaction fails at high context usage (119k/131k), leaving sessions unrecoverable.
-
Whether there is a rate limit, context limit, or model-specific issue affecting KimiClaw browser users.
I have attached screenshots showing the error messages and the client state. I am happy to provide my agents.md, session logs, or any other diagnostic data you need.
Thank you for your urgent attention. My development is fully blocked until this is resolved.
Best regards,
+UPDATE I did /new and run one promt and get the following status
![]() OpenClaw 2026.3.13 (61d171a)
OpenClaw 2026.3.13 (61d171a)
![]() Model: kimi-coding/k2p5 ·
Model: kimi-coding/k2p5 · ![]() api-key (env: KIMI_API_KEY)
api-key (env: KIMI_API_KEY)
![]() Tokens: 101k in / 1 out ·
Tokens: 101k in / 1 out · ![]() Cost: $0.0000
Cost: $0.0000
![]() Context: 101k/131k (77%) ·
Context: 101k/131k (77%) · ![]() Compactions: 25
Compactions: 25
![]() Session: agent:main:main • updated just now
Session: agent:main:main • updated just now
![]() Runtime: direct · Think: high · Reasoning: stream
Runtime: direct · Think: high · Reasoning: stream
![]() Queue: collect (depth 0)
Queue: collect (depth 0)
so actually my KimiClaw is stuck again. Next i did /compact and now it
Compacted (100k → 17k) • Context 17k/131k (13%)
I dont understand such Kimi`s behavior and what should i do next.
+UPDATE Request timed out before a response was generated. Please try again, or increase `agents.defaults.timeoutSeconds` in your config.
+UPDATE 1 hour left since /compact and now actual /status is

![]() OpenClaw 2026.3.13 (61d171a)
OpenClaw 2026.3.13 (61d171a)
![]() Model: kimi-coding/k2p5 ·
Model: kimi-coding/k2p5 · ![]() api-key (env: KIMI_API_KEY)
api-key (env: KIMI_API_KEY)
![]() Tokens: 108k in / 1 out ·
Tokens: 108k in / 1 out · ![]() Cost: $0.0000
Cost: $0.0000
![]() Context: 108k/131k (83%) ·
Context: 108k/131k (83%) · ![]() Compactions: 26
Compactions: 26
![]() Session: agent:main:main • updated just now
Session: agent:main:main • updated just now
![]() Runtime: direct · Think: high · Reasoning: stream
Runtime: direct · Think: high · Reasoning: stream
![]() Queue: collect (depth 0)
Queue: collect (depth 0)
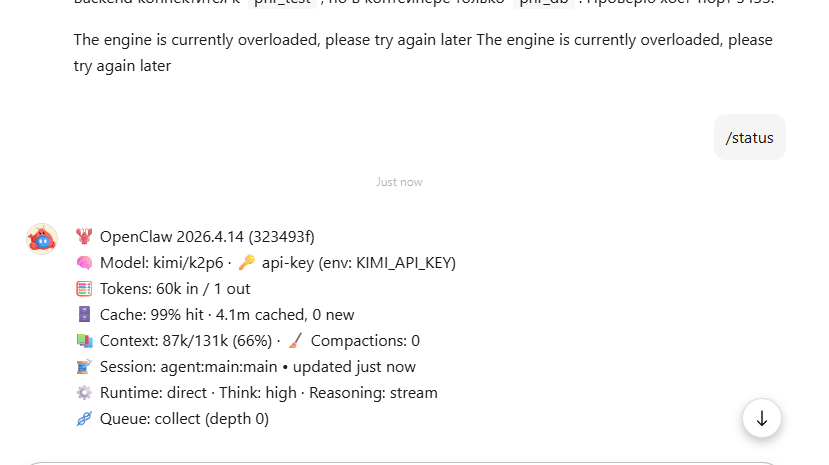
and KIMI again goes The engine is currently overloaded, please try again later The engine is currently overloaded, please try again later
Please help me to stabilize the KIMI Claw!!!